Introduction
Seqera supports running pipelines on several compute platforms including commercial cloud such as AWS and Azure, as well as high-performance computers (HPC). A full list of supported platforms is available in Seqera’s documentation.
To access these compute infrastructures through Seqera, compute environments need to be created and configured on Seqera for each compute infrastructure.
Configuring HPC on the Australian Nextflow Seqera Service
Seqera supports adding compute environments for HPCs that utilise Slurm and PBS Pro workload managers.
Note: Compute environments are shared across all users of the same workspace.
In order to access compute infrastructre, you need to create access credentials. SSH keys or Tower Agents can be used to access the HPC. SSH keys are easier to use but some HPC providers are restricted from sharing SSH keys with a third party (i.e. Seqera Platform). In addition, it can be tricky to use SSH keys if the HPC is within a private network and requires VPN access.
The following instructions are to configure compute environments for HPC through Tower agent credentials.
Steps to configure HPC on the Australian Nextflow Seqera Service within an organisation workspace
Prerequisites for configuration on an organisation workspace:
- You have access to an organisation workspace
- You have an owner or administrator role within this workspace.
The following steps need to be completed in order unless they have been completed before and are to be reused.
- Create Personal Token
- Create Tower Agent credentials
- Configure the compute infrastructure
Detailed Instructions:
- Navigate to the
User Tokensfrom the user menu on the top-right corner:
- Click
Add Tokenand give the token a name. - Keep it safe, create a new one if you lose it and delete lost tokens.
- Use descriptive names.
- Don’t share your token with others.
- After you close the token creation window, you will not be able to view/copy the token any more, but you can update it or delete it.
Note
The same personal access token can be used with multiple Tower agents, however, we recommend creating one access token for each credential or at least for each compute infrastructure.
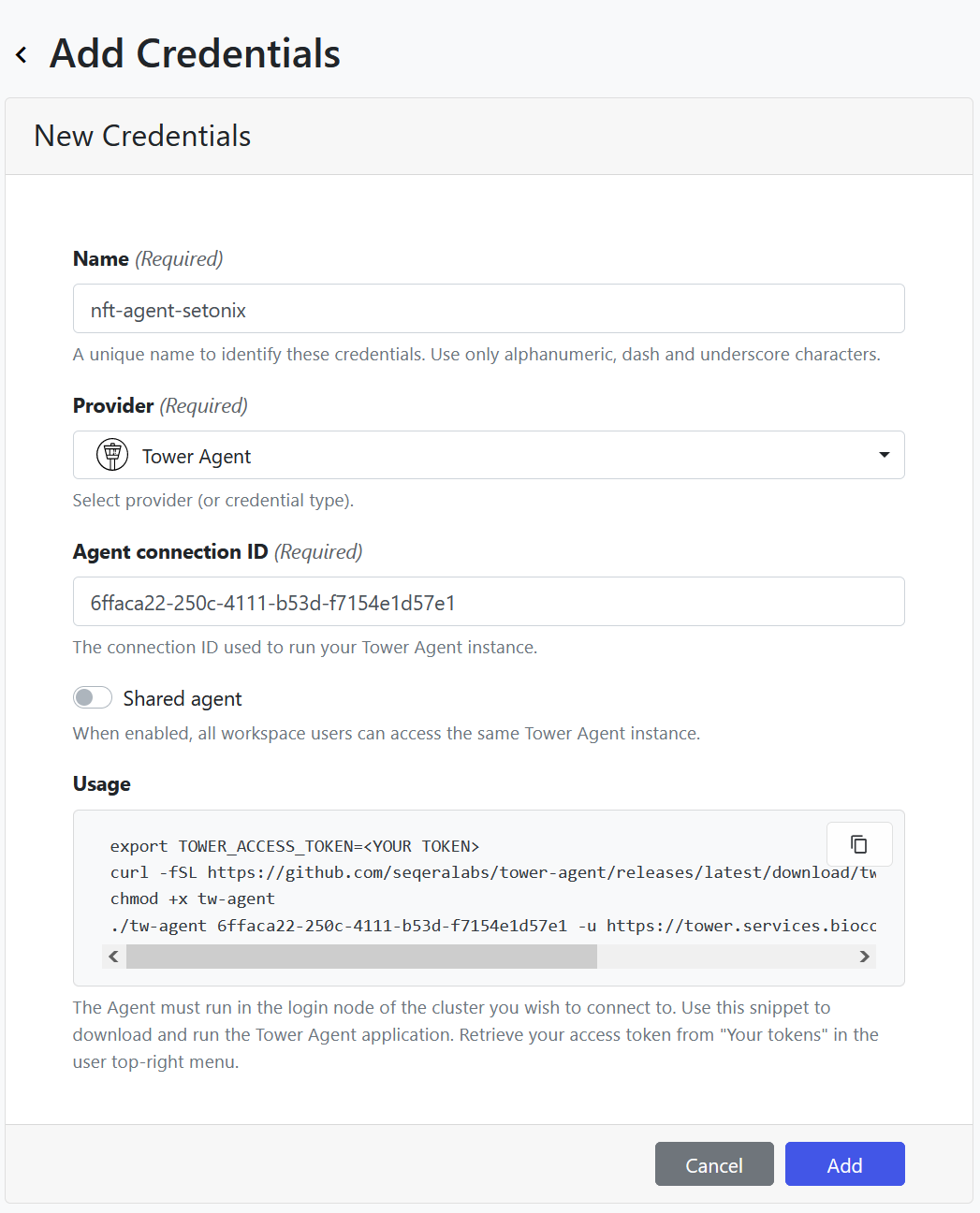
Tower Agent is software that runs on the HPC and communicates with the Seqera API to perform all tasks needed on the HPC, including launching a pipeline and monitoring its execution. For an admin to create a tower agent credential, follow these steps:
- Navigate to the workspace you want to add credentials to, then click on the
Credentialstab. - Click on the
Add Credentialsbutton underCredentialsto create a sharedAgent connection IDfor the Tower Agent. - A wizard interface will appear, with some scripts in the
Usagebox and fields to complete. - Give your credential a descriptive name, this is working at the infrastructure level so we recommend creating different credentials for different environments.
- Keep
Shared agentdisabled. Check the shared agent section of this guide for more details. - Before adding the credential you will need to run the agent on the compute infrastructure. To do this:
- Keep the Agent interface open.
- Log in to infrastructure (the HPC).
- In theory, you can run the Agent from anywhere on the HPC. See our best practices for some recommendations.
- Copy the usage script from the Agent interface to any text editor and edit the access token to provide your own token created above and provide the path to the work directory for the Agent.
- The work directory for the Agent (provided as a parameter in the command) must exist before running the Agent.
- Run the edited script relevant to your infrastructure (PBS or SLURM) bash.
- This script will download the Tower Agent script to the current work directory on the HPC and make it executable.
- Then, it runs the Agent by providing the connection id and access token.
- You can see the Agent running on the terminal. Keep it running.
- Back in the Seqera interface, click
Addto save your credential.
The steps above will help to create the credentials and understand the Agent’s parameters and how it runs. In practice, this can be better optimised by having all scripts and tokens in config files and bash scripts. See [best practice recommendations](/user-guide/hpc-recommendations). The procedure is also described in the Seqera documentation at Quick Start.
Note
Users of the same workspace share credentials, so there is no need to create a credential per user within a workspace.
You might need to create multiple credentials for different compute environments. For example, credentials for your institutional HPC and another credential for AWS account or another national HPC.
- Navigate back to the launchpad page for the workspace you want to add a compute environment to.
- Select the Compute Environments tab in the top navigation bar
- Select
Add Compute Environmentbutton - Give the environment a name
- Make it as descriptive as you like
- For HPC you may wish to configure different compute environments for different project codes, so you could include this in the environment name to easily identify it. For example, specify the name of the HPC and the relevant project code
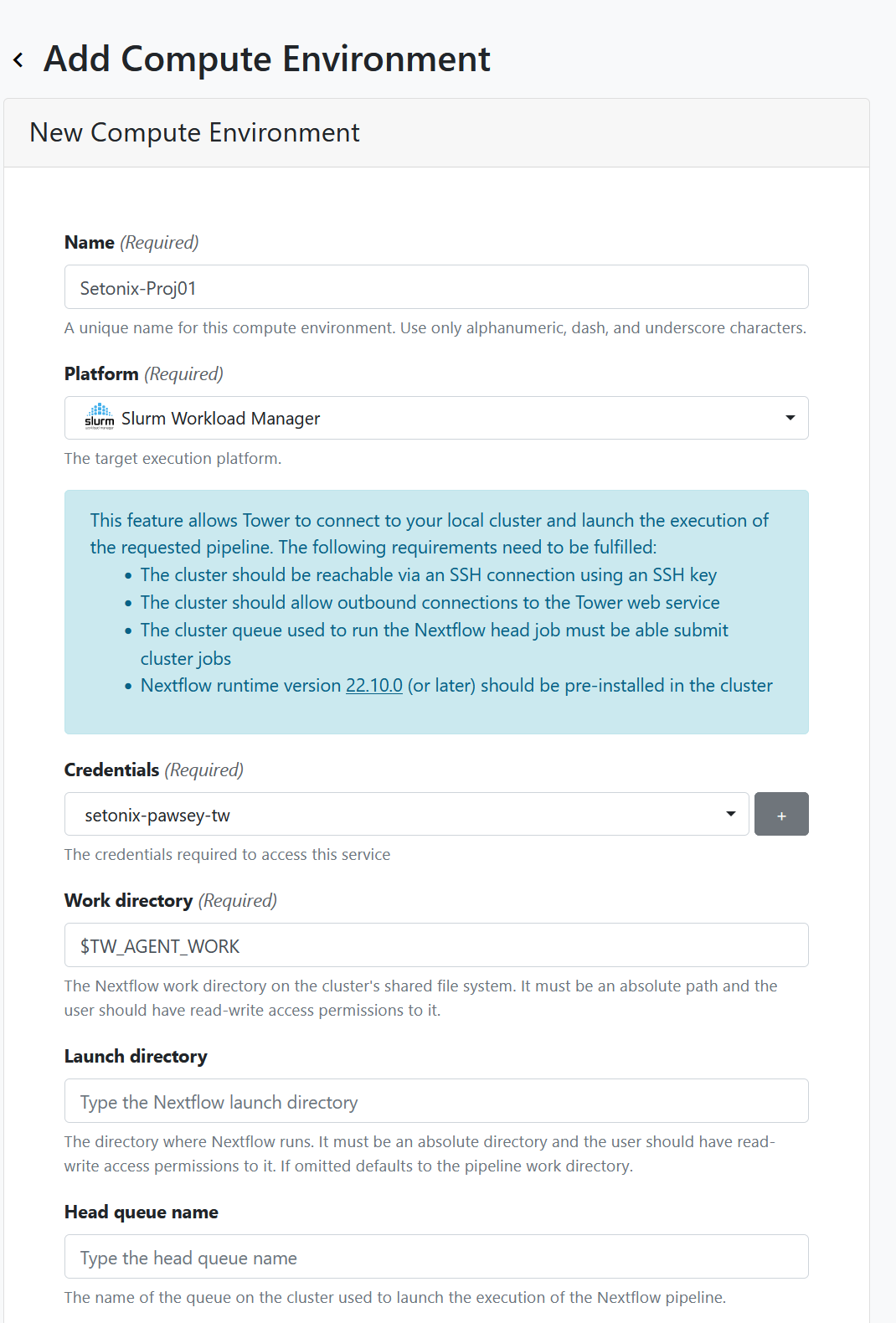
- Select a platform
- This will depend on which infrastructure you are running and what workload managers are available there.
- Examples: For Setonix - SLURM, for Gadi - PBSpro.
- Select workdirectory
- This can remain as
$TW_AGENT_WORKor specify your own
- This can remain as
- Leave the launch directory field empty.
- Provide the launch and compute queue (as available on the HPC).
- We recommend using a queue with long wall time for the launch queue as this is dedicated to the nextflow main process that should run for the whole time of the pipeline execution.
- Compute queue will be used for the tasks of the pipeline so we recommend using the default queue on the HPC.
- The compute queue can be reconfigured during the execution through the pipeline configuration options.
- Select staging options. Under Pre-run script:
- Here you can provide all commands to be executed on the HPC before launching the pipeline including module loading.
- Usually you will need to load Nextflow, singularity, conda, awscli .. if any of them will be used.
- Specify advanced options
- Under head job submit options add project specific and queue data. This configuration is for the job that runs the main nextflow process.
- It is recommended to use 2 CPUs and 8 GB memory for this job.
- Apply head job submit options to compute jobs to ensure your account details get passed on.
- Click on
Addand the compute environment will be created.
Utilising compute environment with Tower Agent
There are a few points to be considered when using Tower Agent:
- The users of a workspace will share the same compute environment and credentials.
- Each user needs to create their own personal access token.
- Each user needs to run Tower Agent on their account on the HPC.
- Each user needs to pass their personal access token and the shared connection id (of the credential) to their instance of Tower Agent on the HPC.
To do that:
- Create a personal access token or use a pre-created access token as described here (access1).
- Obtain the connection id for the compute environment from its credential page (conn_id).
- Run Tower Agent using access1 and conn_id, and an independent work directory (any directory you have access to).
- The compute environment will be available and usable as long as the agent is running.
Note
Tower Agent does not support service accounts on the HPC. In other words, you can not use one Agent for multiple users.
The Agent should be able to access the internet.
Configuring commerical cloud
The easiest way is using AWS Batch and Batch Forge permissions to allow tower to create the batch environment. In order to do this please follow this documentation.
Other infrastructures
Please visit Seqera documentation for more details on configuring for other compute infrastructures such as Azure.
Contributors
Australian BioCommons / Sydney Informatics Hub at the University of Sydney
 Business analyst
Business analyst
Australian BioCommons / University of Melbourne
 Product manager
Product manager
Australian BioCommons / University of Melbourne